
Künstliche Intelligenz kann heute überzeugende Antworten formulieren. Für den Einsatz im Unternehmen reicht das aber nicht. Entscheider und Fachkräfte brauchen mehr als eine plausibel klingende Antwort: Sie müssen nachvollziehen können, woher eine Information stammt, wie sie gefunden wurde und wie belastbar sie ist.
An diesem Punkt scheitern viele KI-Projekte. Die Technologie ist da, aber die Akzeptanz bleibt aus, weil Mitarbeitende den Ergebnissen nicht trauen. In einem begleitenden Beitrag haben wir gezeigt, wie saubere Datenaufbereitung die Grundlage für verlässliche KI-Antworten schafft. Dieser Artikel beschreibt den zweiten Teil: Wie eine Such-Pipeline aus diesen aufbereiteten Daten Antworten mit nachvollziehbaren Quellenangaben erzeugt.
Als Beispiel dient ein Projekt aus der maritimen Industrie, bei dem Tausende E-Mails, Berichte und technische Dokumente einer Schiffsflotte durchsuchbar gemacht werden. Die dort eingesetzten Prinzipien lassen sich auf andere Branchen übertragen, überall dort, wo Unternehmen ihre internen Wissensbestände mit KI erschließen wollen.
Nicht jede Frage braucht eine Suche
Ein häufig unterschätzter Aspekt ist die Eingangsklassifikation. Nicht jede Nachricht eines Nutzers erfordert eine Suche durch den gesamten Datenbestand. Ein “Hallo” oder “Danke” muss keine Datenbank-Abfrage auslösen.
Das System erkennt automatisch, ob eine Nachricht eine echte Sachfrage ist, eine offene Überlegung, eine themenfremde Frage oder ein Gruß. Nur bei Sachfragen wird die vollständige Such-Pipeline aktiviert. Alles andere wird direkt beantwortet oder mit einem klärenden Hinweis versehen.
In unserem Flottenprojekt fallen 15 bis 25 Prozent aller Nachrichten in diese Kategorie: Grüße, Bestätigungen, Nachfragen. Durch die Vorfilterung spart das System pro solcher Nachricht 200 bis 400 Millisekunden und vermeidet unnötige Kosten für ergebnislose Suchvorgänge.
Sollte die Klassifikation einmal fehlschlagen, wird die Nachricht als Sachfrage behandelt. Lieber eine Suche zu viel als eine übersehene Frage.
Gezielt suchen statt alles durchsuchen
Die Qualität einer Antwort hängt davon ab, wie präzise die Suche eingegrenzt wird. Ein System, das bei jeder Frage den gesamten Datenbestand durchsucht, liefert zwar viele Ergebnisse, aber häufig die falschen.
Die Such-Pipeline arbeitet mit mehreren Filterstufen, die den Suchraum schrittweise eingrenzen.
Zuerst die thematische Eingrenzung: Das System erkennt, welche Themengebiete zur Frage passen, und durchsucht nur die relevanten Bereiche. Eine Frage zu Ladungsschäden liefert so keine Ergebnisse zu Motorwartung, auch wenn beide Themen ähnliche Fachbegriffe verwenden.
Dazu kommen strukturelle Filter. In der Flottenverwaltung können Nutzer nach bestimmten Schiffen, Schiffstypen oder Schiffsklassen filtern. Diese Filter arbeiten exakt, nicht auf Basis von Ähnlichkeit. Wer nach einem bestimmten Schiff fragt, bekommt ausschließlich Ergebnisse zu diesem Schiff.
Wenn die thematische Eingrenzung zu wenige Ergebnisse liefert, wird der Filter schrittweise gelockert. So geht keine Information verloren, nur weil sie unter einem leicht abweichenden Thema einsortiert wurde.
Wichtig: Filter merken sich den Kontext. Wenn ein Nutzer einen Schiffsnamen auswählt, gilt dieser Filter auch für Folgefragen innerhalb derselben Unterhaltung. Das entspricht dem natürlichen Gesprächsverhalten. Man wiederholt nicht bei jeder Frage, über welches Schiff man spricht.
Das Ergebnis: Statt 40 Treffern, von denen 30 thematisch nicht passen, erhält das System 40 Treffer mit höherer Relevanz. Dieser Unterschied ist für die Nutzer direkt spürbar, die Antworten werden präziser.
Präzision durch mehrstufige Bewertung
Die erste Suche liefert Kandidaten, aber nicht jeder Kandidat ist gleich relevant. In unseren Tests mit dem Flottendatenbestand hat eine mehrstufige Nachbewertung die Trefferqualität um 20 bis 35 Prozent verbessert.
Das System kombiniert zwei Suchverfahren. Die semantische Suche findet Treffer auf Bedeutungsebene: “Antriebsstörung” wird erkannt, auch wenn im Dokument “Maschinenausfall” steht. Die Schlüsselwortsuche ergänzt exakte Übereinstimmungen, die bei der semantischen Suche verloren gehen können, etwa spezifische Teilenummern oder Referenzcodes.
Nach der ersten Suche bewertet ein spezialisiertes Modell jeden Treffer erneut im direkten Zusammenhang mit der Frage. Diese Nachbewertung ist genauer als die erste Einschätzung, weil sie Frage und Dokument gemeinsam betrachtet statt getrennt. Zusätzlich wird jedes Ergebnis mit seinem Kontext angereichert (etwa dem Betreff der ursprünglichen E-Mail), damit die Bewertung auf einer breiteren Grundlage erfolgt.
Die Kombination beider Verfahren stellt sicher, dass sowohl inhaltlich verwandte als auch exakt übereinstimmende Dokumente gefunden werden. Gemessen an einer reinen Schlüsselwortsuche (die Standardlösung in vielen Bestandssystemen) lag die Trefferquote im selben Testdatenbestand um 35 bis 67 Prozent höher.
Auch hier gilt Ausfallsicherheit: Sollte der Bewertungsdienst nicht erreichbar sein, werden die Ergebnisse der ersten Suche direkt verwendet. Die Nutzer erhalten weiterhin Antworten, möglicherweise etwas weniger präzise sortiert, aber niemals eine leere Seite.
Zusammenhänge erkennen statt Fragmente liefern
Viele Vorgänge bestehen aus mehreren zusammenhängenden Nachrichten. Ein technisches Problem wird gemeldet, untersucht und gelöst, verteilt über einen ganzen E-Mail-Verlauf. Wenn das System nur einzelne Nachrichtenfragmente findet, fehlt der Zusammenhang.
Die Such-Pipeline behandelt zusammenhängende Vorgänge daher als Einheit. Suchergebnisse aus demselben E-Mail-Verlauf werden gruppiert, sodass die KI den gesamten Ablauf sieht: Problem, Untersuchung, Lösung. Bei der Datenaufbereitung entstehen außerdem Zusammenfassungen ganzer Vorgänge, die den vollständigen Ablauf in kompakter Form abbilden.
Das hilft besonders bei Fragen wie “Wie wurde das Problem mit dem Zylinderschaden auf Schiff X gelöst?”. Ein einzelnes Nachrichtenfragment würde vielleicht nur “Liner ersetzt” enthalten, ohne den Kontext: warum, wann und durch wen. Die Zusammenfassung des gesamten Vorgangs liefert die vollständige Antwort.
Quellenangaben als Vertrauensanker
Der Unterschied zwischen einer KI-Antwort, der man vertraut, und einer, die man hinterfragt, liegt in den Quellenangaben. Jede Aussage in der Antwort wird mit einer konkreten Quelle verknüpft: der ursprünglichen E-Mail, dem Anhang, der Seitenzahl.

Jede Quellenangabe durchläuft dabei eine Validierung:
- Jede zitierte Quelle wird geprüft: Existiert das referenzierte Dokument, und ist es abrufbar?
- Ungültige Verweise (etwa wenn die KI eine nicht existierende Quelle nennt) werden automatisch entfernt, bevor die Antwort den Nutzer erreicht.
- Die Prüfung aller Quellen erfolgt parallel und beeinflusst die Antwortzeit kaum.
- Werden mehrere Stellen aus demselben Dokument zitiert, erscheint das Dokument in der Quellenübersicht nur einmal.
Für die Nutzer heißt das: Jede angezeigte Quelle führt zu einem echten Dokument. Ein Klick öffnet das Originaldokument mit hervorgehobener Textstelle, sodass sofort sichtbar ist, woher die Information stammt. Bei Anhängen lässt sich die Originaldatei herunterladen oder zur übergeordneten E-Mail navigieren.
Nachvollziehbare Quellenangaben sind der wichtigste Faktor für Vertrauen. Mitarbeitende können jede Aussage eigenständig prüfen, bevor sie darauf Entscheidungen aufbauen. Und selbst wenn ein Nutzer eine Unterhaltung Tage später erneut öffnet, sind alle Quellenangaben erhalten: mit funktionierenden Links und korrekten Verweisen. In der Flottenverwaltung werden Vorgänge oft über Wochen bearbeitet, und die Quellen müssen auch beim zweiten oder dritten Blick abrufbar sein.
Antworten, die sofort sichtbar werden
Eine vollständige Suchanfrage dauert typischerweise drei bis acht Sekunden: von der Analyse der Frage über die Suche bis zur Formulierung der Antwort. Ohne Rückmeldung würden Nutzer in dieser Zeit annehmen, dass das System nicht reagiert.
Antworten werden daher wortweise gestreamt, sobald sie generiert werden. Die erste Reaktion erscheint in unter einer halben Sekunde. Während der Suchphase informieren Fortschrittsmeldungen den Nutzer über den aktuellen Stand: “Themen werden durchsucht…”, “Dokumente werden durchsucht…”, “Ergebnisse werden bewertet…”.
Die Quellenangaben werden nach Abschluss der Antwort als eigener Datensatz übermittelt und automatisch in den Text eingefügt. Sollte die Übermittlung einmal verzögert sein, greift nach drei Sekunden eine Rückfalllösung, die die Quellen in vereinfachter Form darstellt. So sind Quellenangaben immer sichtbar, unabhängig von der Netzwerkqualität.
Das mag wie ein technisches Detail wirken. Aber es hat direkten Einfluss auf die Nutzerakzeptanz. Ein System, das schnell und sichtbar reagiert, wird häufiger genutzt als eines, das mehrere Sekunden lang scheinbar nichts tut.
Zuverlässigkeit auch bei Störungen
Die Such-Pipeline hängt von mehreren externen Diensten ab: Suchindizes, Bewertungsdienste, Sprachmodelle. Jeder davon kann vorübergehend ausfallen. Ein System, das bei jeder Störung eine Fehlermeldung anzeigt, verliert schnell das Vertrauen der Nutzer.
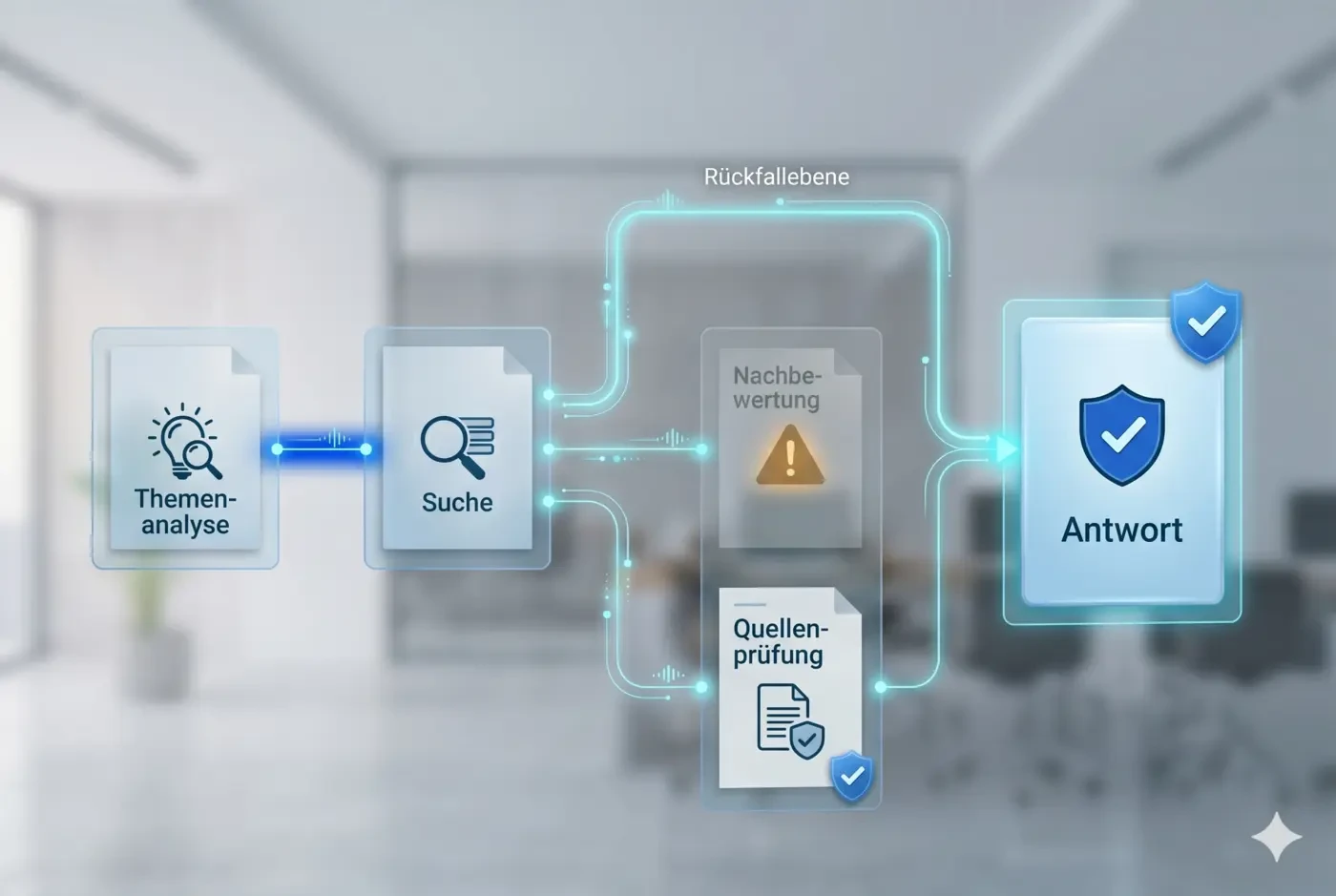
Die gesamte Pipeline folgt daher dem Prinzip der kontrollierten Verschlechterung: Jede Stufe hat eine definierte Rückfallebene.
- Fällt die Themenanalyse aus, wird breiter gesucht: mehr Ergebnisse, aber weiterhin Antworten.
- Fällt die Nachbewertung aus, werden die Ergebnisse der ersten Suche verwendet.
- Können Quellen nicht vollständig geprüft werden, werden sie als “nicht verifiziert” gekennzeichnet, aber dennoch angezeigt.
- Sensible Informationen in Fehlermeldungen werden automatisch bereinigt, bevor sie protokolliert werden.
Für den Nutzer heißt das: Das System liefert immer eine Antwort. Die Qualität kann in Ausnahmefällen etwas geringer sein, aber es gibt keine leeren Bildschirme und keine kryptischen Fehlermeldungen. Im maritimen Kontext, wo Entscheidungen zeitkritisch sein können, ist das besonders relevant.
Lernen und Verbessern durch Transparenz
Ein Suchsystem wird nicht einmal eingerichtet und bleibt dann stehen. Es muss besser werden. Dafür braucht es Sichtbarkeit, denn ohne sie bleiben Qualitätsprobleme unbemerkt. Schlechte Antworten erzeugen keine Fehlermeldungen, sie erzeugen stilles Misstrauen.
Jeder Suchvorgang wird daher protokolliert: Welche Themen wurden erkannt? Welche Dokumente gefunden? Wie hat die Nachbewertung die Reihenfolge verändert? Welche Quellen wurden zitiert?
Nutzer können zusätzlich direkt Rückmeldung geben, positiv oder negativ, zu jeder Antwort. Diese Rückmeldungen werden mit dem vollständigen Suchvorgang verknüpft. So lässt sich gezielt analysieren, bei welchen Themen, Schiffen oder Fragetypen die Ergebnisse schwächeln.
Außerdem werden technische Kennzahlen erfasst, etwa wie effizient das System seinen Zwischenspeicher nutzt. Daraus lassen sich Optimierungen ableiten, die Antwortgeschwindigkeit und Betriebskosten verbessern, ohne dass die Nutzer etwas davon mitbekommen.
Dieser Rückkopplungskreislauf verwandelt Nutzererfahrung in konkrete Verbesserungen. Das System wird mit der Zeit besser auf die tatsächlichen Fragen und Abläufe zugeschnitten. Für Unternehmen heißt das: Die Investition in ein KI-Suchsystem ist kein einmaliger Aufwand, das System entwickelt sich mit.
Fazit
Vertrauen in KI-gestützte Suche entsteht nicht durch bessere Sprachmodelle allein. Es entsteht durch ein System, das seine Quellen offenlegt und auch bei Teilausfällen zuverlässig reagiert.
Die hier beschriebenen Bausteine (Eingangsklassifikation, mehrstufige Bewertung, validierte Quellenangaben, Streaming, kontrollierte Verschlechterung, Rückkopplung) greifen ineinander. Einzeln betrachtet sind es technische Details. Zusammen ergeben sie ein System, das Mitarbeitende tatsächlich benutzen, weil sie den Ergebnissen trauen.
Für den Mittelstand heißt das: KI zur Erschließung interner Wissensbestände ist machbar, wenn der Ansatz stimmt. Unsere Erfahrung aus der maritimen Branche bestätigt das. Sobald Mitarbeitende sehen, woher eine Antwort kommt, und das System auch bei Störungen antwortet, verschwindet die Skepsis. KI wird dann kein Sonderthema mehr, sondern ein Arbeitsmittel wie die E-Mail-Suche.
Interessiert, wie Ihr Unternehmen von einer intelligenten, vertrauenswürdigen KI-Suche profitieren kann? Kontaktieren Sie uns. Wir beraten Sie gerne unverbindlich.